Building personal AI tooling with LinkedIn and Notion
I’m on the job market. I don’t mind, redundancies are a part of life in tech in 2025, and I’m ready for something new. What I do mind, though, is that I have to spend my time on LinkedIn. It’s no secret that the powers that be at LinkedIn have decided they would rather run a social media site than a boring old jobs platform, and the UX is geared towards maximising engagement rather than towards providing a pleasant, efficient job-hunting experience.
So I’ve done what any product-oriented data scientist with time on their hands would do: I started working on building the experience I wish LinkedIn provided. The goal here isn’t to build a product, it’s to create a tool that makes my own life easier, to play with some interesting technologies, and to have fun. Here’s what I got up to.
A good rule for AI/automation projects is to start by clearly defining the steps I would take if I were to do this manually. In this case, these would be:
- Log in to LinkedIn
- Run a search, e.g. “Data Scientist” roles, in the UK, and remote.
- Skim through the results page and click into any roles that look relevant.
- Read the full ad for any potentially relevant roles. If still interested, add them my TODO list. A major annoyance at this point is that I’ll often end up reading the same irrelevant posting multiple times, since LinkedIn will keep showing it to me unless I save it.
I’m not going to automate the process of actually applying for jobs, even though it wouldn’t be hard: recruiters don’t want that, LinkedIn doesn’t want that, and I’m confident enough in my own writing that I’d rather write my own cover letters, thank you very much.
Data #
The first step is to download a collection of potentially relevant jobs from LinkedIn. This process can be done using web browser automation tools like selenium, playwright, or, the cool new kid on the block, pydoll. I tried pydoll, found the features I need either don’t exist yet or aren’t documented, and promptly switched to selenium, which worked a treat.
You can find my actual code here, including some useful but not very interesting stuff setting up an SQLite database, but at a high-level, what this does is:
- Opens a chrome window, navigates to the LinkedIn login page, reads my email and password from environment variables, enters them in the appropriate places, and triggers the login button.
- Waits for me to manually run a search and reach the search results page, and then type in a label for this search at the terminal.
- For every job posting on the open search results page, clicks on the the posting in the menu, waits for the page to load, and then saves the entire DOM to a SQLite database.
- If there is a “Next page” button, clicks it and repeats step 3. Otherwise, stops.
Here’s it in action.
Extraction #
At this point, I’ve got a SQLite database full of HTML pages. The next step is to extract out the text of the job advert from each one. A bit of trial and error produces the function below. The crap_classes capture elements that are included in the job detail element, but which I don’t want to include in my output. There’s definitely room for refinement here.
from bs4 import BeautifulSoup
def get_listing_text(html: str) -> str:
"""Extract job listing from HTML of a linkedin job page"""
soup = BeautifulSoup(html, "html.parser")
if soup.body is None:
raise ValueError("HTML has no body")
details = soup.body.find(class_="jobs-search__job-details--wrapper")
if details is None:
raise ValueError("No job details element found")
crap_classes = [
"job-details-connections-card",
"jobs-premium-applicant-insights",
"highcharts-wrapper",
]
for cls in crap_classes:
instances = details.find_all(class_=cls) # type: ignore
for x in instances:
x.decompose()
return details.get_text(separator="\n", strip=True)
Now for the AI. I don’t want to read every single job advert. Instead, I want to extract out key details that I can use to identify the ads I actually want to read. To do this, I use structured outputs to force the LLM to generate outputs that follow a schema that I provide. In this case, my schema is
from typing import Literal
from pydantic import BaseModel
class ExtractedJobPosting(BaseModel):
job_title: str
company_name: str
industry: str | None = field("Industry for the role, e.g. 'Finance', 'Health', 'Education', etc.")
location: str
salary: str | None = field("e.g. '£100,000 - £120,000'")
contract_type: Literal["permanent", "fixed contract", "UNKNOWN"]
office_type: Literal["office", "hybrid", "remote", "UNKNOWN"]
# More open-ended stuff
company_description: str = field("What does the company do? One sentence")
company_size: str | None
job_description: str = field("What does the job entail? One sentence")
skills: str = field(
"What skills are required for the job? One sentence, be concise"
)
…and my system prompt is
Below, you are provided with a job advert. Extract the information from the job advert and return it in the structure specified.
Be aware that some adverts will be posted by a recruitment agency, and for these roles, the “About the company” information will refer to the agency, not the company offering the role. If this is the case, ignore the “About the company” information and extract the relevant information from the job description.
Obviously, the section about recruitment agencies was added based on issues with the first iteration.
Running this against all of the downloaded jobs, and combining the results with some metadata, I end up with JSON records that look like this:
[
{
"job_title": "Senior Machine Learning Engineer",
"company_name": "Srotas Health",
"industry": "Health",
"location": "United Kingdom",
"salary": null,
"contract_type": "permanent",
"office_type": "remote",
"company_description": "Srotas Health Ltd is a UK-based life sciences and healthcare technology company dedicated to transforming the clinical trial industry through AI-driven solutions.",
"company_size": "2-10 employees",
"job_description": "This role entails developing and deploying cutting-edge AI models for clinical trials and healthcare applications, specifically focusing on Large Language Models (LLMs) and inference optimisation.",
"skills": "Strong experience in AI/ML development, particularly with LLMs and biomedical NLP.",
"title": "Senior Machine Learning Engineer",
"job_id": "4167153610",
"url": "https://www.linkedin.com/jobs/search/?currentJobId=4167153610&distance=25&f_WT=2&geoId=101165590&keywords=data%20scientist&origin=JOBS_HOME_KEYWORD_HISTORY&refresh=true",
"search_label": "UK remote",
"capture_time": "2025-03-15 14:19:49"
},
{
"job_title": "Senior Data Scientist, Product",
"company_name": "Wordwall",
"industry": "E-Learning",
"location": "United Kingdom (Remote)",
"salary": "\u00a350 - 60k per year",
"contract_type": "permanent",
"office_type": "remote",
"company_description": "Wordwall.net makes creating custom teaching materials easy.",
"company_size": "11-50 employees",
"job_description": "The job entails analyzing user behavior and collaborating with the development team to translate this analysis into actionable insights.",
"skills": "Required skills include expertise in databases, statistics, programming, and advanced spreadsheets.",
"title": "Senior Data Scientist, Product",
"job_id": "4177728128",
"url": "https://www.linkedin.com/jobs/search/?currentJobId=4177728128&distance=25&f_WT=2&geoId=101165590&keywords=data%20scientist&origin=JOBS_HOME_KEYWORD_HISTORY&refresh=true",
"search_label": "UK remote",
"capture_time": "2025-03-15 14:19:54"
},
{
"job_title": "Senior Data Engineer",
"company_name": "CereCore",
"industry": "IT Services and IT Consulting",
"location": "United Kingdom (Remote)",
"salary": null,
"contract_type": "fixed contract",
"office_type": "remote",
"company_description": "CereCore\u00ae provides EHR consulting and implementation services to hospitals and health systems across the U.S. and the U.K.",
"company_size": "501-1,000 employees",
"job_description": "The role involves developing ETL pipelines, transforming healthcare data, and ensuring high-performance data workflows.",
"skills": "Strong expertise in SQL and proficiency in Python, PySpark, or Apache Airflow for ETL development.",
"title": "Senior Data Engineer",
"job_id": "4159496781",
"url": "https://www.linkedin.com/jobs/search/?currentJobId=4159496781&distance=25&f_WT=2&geoId=101165590&keywords=data%20scientist&origin=JOBS_HOME_KEYWORD_HISTORY&refresh=true",
"search_label": "UK remote",
"capture_time": "2025-03-15 14:20:00"
},
{
"job_title": "Head of Data Science & AI",
"company_name": "Careerwise",
"industry": "Business Consulting and Services",
"location": "London Area, United Kingdom",
"salary": "\u00a3100/yr - \u00a3120/yr",
"contract_type": "permanent",
"office_type": "remote",
"company_description": "Careerwise is a business consulting and services firm focusing on applied thinking in the IT industry.",
"company_size": "11-50 employees",
"job_description": "Lead the data and AI-driven transformation of the organization and client solutions by developing and implementing data strategies and governance frameworks.",
"skills": "Experience in Databricks, PySpark, Azure Data Factory, Knowledge Graphs, Power BI, and advanced AI and machine learning techniques.",
"title": "Head of Data Science & AI",
"job_id": "4179442562",
"url": "https://www.linkedin.com/jobs/search/?currentJobId=4179442562&distance=25&f_WT=2&geoId=101165590&keywords=data%20scientist&origin=JOBS_HOME_KEYWORD_HISTORY&refresh=true",
"search_label": "UK remote",
"capture_time": "2025-03-15 14:20:05"
},
// ...
]
Personalisation #
Now that I’ve got all of this information in a nice format, how do I identify the roles that are of interest to me personally? First, a tangent about search and recommendations. In some situations, a search is easy to define: the searcher knows what they’re looking for, and the right result either exists in the set and they want to find it, or it doesn’t, in which case they don’t want anything. In others, it’s more of a negotiation. I don’t have a perfect job in mind, and I can’t even provide a precise list of criteria that would dictate whether or not I’m interested in something. Instead, I want explore what options are out there, but I want to explore the most potentially relevant options first, rather than wasting my time trawling everything. This leaves room for serendipity: there will be kinds of jobs out there that I hadn’t even realised I would be interested in.
I thought about a few ways of approaching this. One is to use active search over latent space. This entails first generating embedding vectors for each job. Then, I manually select a few at random and annotate them (e.g. give them a score from +2 for definitely interested to -2 for definitely not interested). I can then fit a model to suggest other jobs that I might be interested in, which I annotate, and feed back into the model to retrain and get even better suggestions. This isn’t the best approach here though. For a start, I don’t have enough data for this to be worth the effort. Beyond that, I have have some explicit knowledge that I can articulate here - for instance, I’m not interested in data engineering roles. I could encode this information by giving negative scores to lots of data engineering job ads until the model gets the idea, but this is very inefficient. Best to park the embeddings for now.
What about generative language models? I could specify some criteria that jobs should meet before I look at them, but as I said above, that doesn’t leave any room for exploration. The approach I’ve taken instead is to use an LLM to classify jobs according to some criteria relevant to me:
YNM = Literal["yes", "no", "maybe"]
class JobEvaluation(BaseModel):
role_type: YNM = field(
"I'm interested in data science roles, e.g. data scientist, AI engineer, etc., but not data engineer, software engineer, data analyst, etc."
)
seniority: YNM = field("I'm interested in senior roles (or higher).")
location: YNM = field(
"Is the role either remote or based in Ireland? Say 'no' for roles that require being in London every week"
)
positive_industry: YNM = field(
"I'm particularly interested in roles that have a positive social impact, e.g. mental health, education, climate change, etc. Is this role a match?"
)
negative_industry: YNM = field(
"I'm not interested in industries such as finance, cryptocurrency, marketing, defence etc. Is this role in one of these industries?"
)
startup: YNM = field(
"I prefer startups to large, well-established companies. Is this role with a younger/smaller company?"
)
salary: YNM = field("Does this role pay more than £80K (or equivalent)?")
def evaluate_jobs(jobs: list[JobPosting], llm: OpenAIClient) -> list[JobEvaluation]:
prompt = """
Read the job posting below and evaluate whether it is a good match for me.
Provide your response in the format provided.
"""
job_texts = [listing_to_text(job) for job in jobs]
return llm.llm_batch(
prompt, job_texts, response_format=JobEvaluation, progress_bar=True
)
I won’t automatically apply for jobs that meet all of those criteria, or automatically ignore jobs that meet none of them, but creating these fields make the process of manually looking at jobs much more efficient, as it gives me a “default decision”. I would typically start by looking at the jobs that meet every criterion, and asking, for each one, “is there any reason I actually wouldn’t apply for this?”, before moving to the jobs that meet no criteria, skimming the titles, and asking “is there any reason I should consider this?”. After that, I can move to the jobs that meet some criteria but not others, and take a similar approach.
Export to Notion #
Pipelines, JSON files, and jupyter notebooks are all well and good, but eventually I need to sit down and actually do the administrative work of looking at the individual jobs, making notes, and tracking my progress. I’m a big fan of Notion and their developer API as an incredibly quick way of creating a UI for your data.
The key abstraction here is the database. A Notion database is a table, with columns for different fields, and each “row” of the table corresponds to a Notion page, with values for each of the columns, plus the actual body of the page. With a little boilerplate, you can push pandas dataframes to Notion as databases, or pull data from these databases back into pandas. This is very useful both for personal stuff like the current project, or for building prototypes for your colleagues at work if your company uses Notion.
To do this, you’ll need to create an internal Notion integration, and generate and save an API key for it. You’ll also need to give your integration (sometimes called Connections) access to the page where you want your database to go (see screenshot).
I’ll skip over the code for creating the database and pushing data to it, but the end result is shown below.
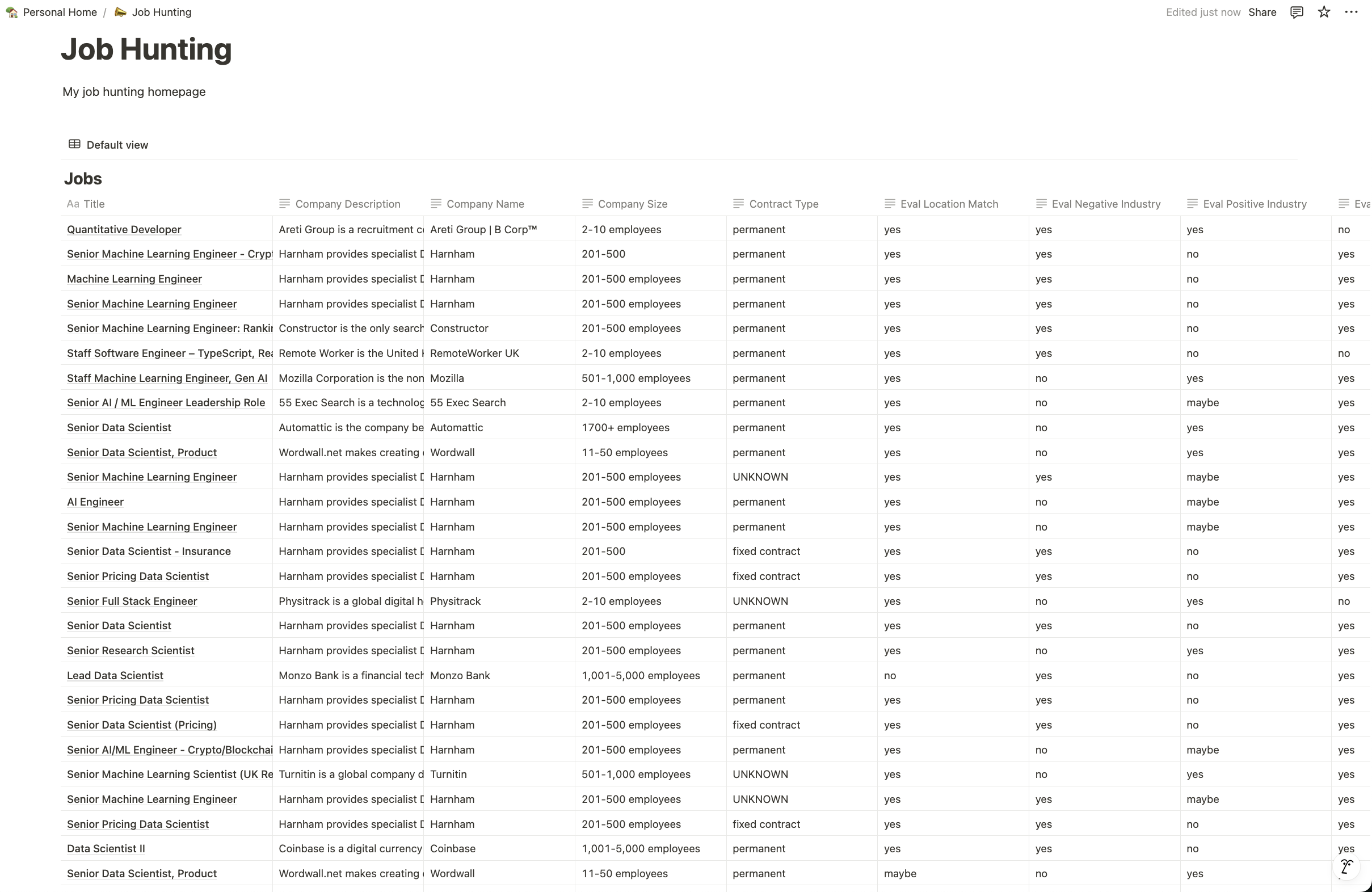
This is now my personal job hunting dashboard. From here, I can filter by the various evaluation criteria described above, tag jobs (e.g. Not interested, Consider, Apply, In Progress), and do all of the other stuff that people use Notion for.
Next Steps #
That’s enough coding for now, because I need to go and actually write some cover letters.
There are plenty of obvious improvements that could be made to this code, although I’ll likely not get around to doing most of them.
- Handle updates: In a week from now, there will be new roles on LinkedIn. Or I might want to add the results of another search to this database. I’ll need to add logic to prevent roles being added and processed if they’re already in the database. Including this logic in the first iteration of the tool wouldn’t be very agile.
- Remove duplicates:
Even after removing jobs that have the same
currentJobIdURL parameter, there are plenty of identical ads, and also ads that aren’t identical, but clearly are for the same role. I could do with better de-duplication here. - Better evaluation criteria: There’s room for improvement in the personal criteria I ask the LLM to apply to the roles, and the prompt for doing this. There’s lots of scope for prompt engineering here, but only after I get through the roles I already have lined up. I may also be able to use the descriptions for the jobs I am applying for to automatically write some better criteria.
- Embeddings: Now that I’ve annotated the jobs I will and won’t apply for, it might be worth training a classifier on this data for use on new roles. We’ll see.
Creating a Product #
I’m unlikely to turn this into a fully-fledged product - I’m happy to run this locally myself, and I’ve shared the code so that anyone else interested can do the same. It would also probably violate LinkedIn’s terms of use, although I haven’t checked this. But it’s useful to think about how this could be turned from a local prototype into the real deal. Here’s how I would go:
- The process of clicking through search results and saving the ads can be implemented as a browser extension.
- Instead of saving to a local SQLite database, the page HTML can be sent to an API. This would run the data extraction and evaluation steps in an event-driven way for each job as it comes in. The API would also have to handle avoiding duplication.
- This API could push pages to a Notion database (using a publish Notion Integration), or I could set up a dedicated (e.g. postgres) database for this product and build a control panel. But then I would have to deal with building a UI, managing user auth, etc., etc.