- Eoin Travers | AI & Data Science/
- Blog Posts/
- Group coordination, automatic clustering, and scikit-learn /
Group coordination, automatic clustering, and scikit-learn
Table of Contents
In a pretty cool experiment run at Tate Modern last year, we put visitors to the gallery into groups of 7, blindfolded them, and asked to to march in time at a given tempo. We’re using this data to explore how people coordinate with each other in groups.
One problem, however, is that people don’t always keep perfect time.
Often, they would skip a few beats, step more than once in a single beat, or start late.
The challange was to find a way to automatically cluster the data,
so we can say this footstep and this footstep belong to this beat,
while this other other footstep belongs to a different beat.
In this post, I outline how I achieved this using python’s
scikit-learn.
The Data #
First, let’s take a look at the raw data.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
import seaborn as sns
from sklearn import cluster as skcluster
# Plot settinngs
sns.set_style('whitegrid')
mpl.rcParams['figure.figsize'] = (8, 6)
mpl.rcParams['font.size'] = 18
all_data = pd.read_csv('data/raw.csv')
all_data.head()
| group | block | camera | subject | step | time | isi | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | A | RA | 1 | 1.534 | NaN |
| 1 | 1 | 1 | A | RA | 2 | 2.037 | 0.503 |
| 2 | 1 | 1 | A | RA | 3 | 2.519 | 0.482 |
| 3 | 1 | 1 | A | RA | 4 | 3.012 | 0.493 |
| 4 | 1 | 1 | A | RA | 5 | 3.467 | 0.455 |
print('We have %i rows, and %i columns.\n' % all_data.shape)
print('Unique values (of index columns):')
for col in ['group', 'block', 'camera', 'subject']:
print('- "%s"\n %s' % (col, str(all_data[col].unique())))
We have 30805 rows, and 7 columns.
Unique values (of index columns):
- "group"
[ 1 2 3 4 5 6 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
26 27 7]
- "block"
[1 2]
- "camera"
['A' 'B']
- "subject"
['RA' 'S2' 'S4' 'S5' 'S6' 'S1' 'S3']
We have data from 27 groups, who each completed two blocks.
Each group consisted of 7 people (6 subjects, and research assistant).
For each step by each person,
we have coded the time since the start of the recording (in seconds),
and the step number (step 1, 2, 3, etc., for that person, in that recording).
Checking Alignment #
Next, let’s extract data from group 1, block 1, and represent it using a wide (participant × step) data frame of step times.
def select_wide_data(all_data: pd.DataFrame,
group: int, block: int) -> pd.DataFrame:
'''Get wide data for this group, in this block'''
mask = (all_data['group']==group) & (all_data['block']==block)
df = all_data[mask] # Long format
dfx = df.pivot_table(index='subject', columns='step', values='time') # Wide format
return dfx
group = 1
block = 1
dfx = select_wide_data(all_data, group, block)
dfx
| step | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | ... | 80 | 81 | 82 | 83 | 84 | 85 | 86 | 87 | 88 | 89 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| subject | |||||||||||||||||||||
| RA | 1.534 | 2.037 | 2.519 | 3.012 | 3.467 | 3.899 | 4.382 | 4.890 | 5.354 | 5.823 | ... | 40.102 | 40.607 | 41.088 | 41.577 | 42.061 | 42.549 | 43.004 | NaN | NaN | NaN |
| S1 | 2.229 | 2.666 | 3.087 | 3.578 | 4.045 | 4.558 | 5.007 | 5.439 | 5.950 | 6.433 | ... | 40.269 | 40.706 | 41.247 | 41.721 | 42.231 | 42.744 | 43.226 | NaN | NaN | NaN |
| S2 | 0.751 | 1.158 | 1.619 | 2.046 | 2.509 | 2.973 | 3.418 | 3.938 | 4.437 | 4.879 | ... | 38.713 | 39.197 | 39.660 | 40.118 | 40.619 | 41.097 | 41.610 | 42.095 | 42.583 | 43.082 |
| S3 | 1.120 | 1.683 | 2.173 | 2.598 | 3.027 | 3.610 | 4.028 | 4.523 | 4.969 | 5.503 | ... | 39.273 | 39.767 | 40.236 | 40.688 | 41.198 | 41.657 | 42.219 | 42.671 | 43.253 | NaN |
| S4 | 1.293 | 2.166 | 2.586 | 2.976 | 3.500 | 3.906 | 4.431 | 4.926 | 5.843 | 6.355 | ... | 40.093 | 40.613 | 41.062 | 41.524 | 42.120 | 42.565 | 43.062 | NaN | NaN | NaN |
| S5 | 1.027 | 1.536 | 2.007 | 2.508 | 2.933 | 3.370 | 3.929 | 4.366 | 4.855 | 5.362 | ... | 39.227 | 39.675 | 40.214 | 40.692 | 41.181 | 41.684 | 42.168 | 42.645 | 43.127 | NaN |
| S6 | 0.582 | 1.131 | 1.666 | 2.096 | 2.534 | 2.952 | 3.480 | 3.954 | 4.432 | 4.910 | ... | 38.807 | 39.230 | 39.716 | 40.130 | 40.696 | 41.137 | 41.641 | 42.103 | 42.655 | NaN |
7 rows × 89 columns
Which steps belong to which beat clusters? We’ll start by assuming that everyone was perfectly coordinated, so that step (n) for every participant belongs to cluster (n). This is encoded in the participant × step cluster matrix, below.
n_subjects, n_times = dfx.shape
steps = np.arange(n_times)
subjects = np.arange(n_subjects)
cluster_ids = dfx.columns.values
initial_cluster_matrix = np.repeat(cluster_ids, n_subjects).reshape((n_times, n_subjects)).T
initial_cluster_matrix
array([[ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32,
33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48,
49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64,
65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80,
81, 82, 83, 84, 85, 86, 87, 88, 89],
[ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32,
33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48,
49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64,
65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80,
81, 82, 83, 84, 85, 86, 87, 88, 89],
[ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32,
33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48,
49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64,
65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80,
81, 82, 83, 84, 85, 86, 87, 88, 89],
[ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32,
33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48,
49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64,
65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80,
81, 82, 83, 84, 85, 86, 87, 88, 89],
[ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32,
33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48,
49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64,
65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80,
81, 82, 83, 84, 85, 86, 87, 88, 89],
[ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32,
33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48,
49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64,
65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80,
81, 82, 83, 84, 85, 86, 87, 88, 89],
[ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32,
33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48,
49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64,
65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80,
81, 82, 83, 84, 85, 86, 87, 88, 89]])
To see how sensible this clustering is, let’s produce a raster plot of all the data from this block. This shows the time of every step for every participant, along with the cluster that step is assigned to (colour-coded, and with numeric labels).
def raster_plot(cluster_matrix: np.ndarray, dfx: pd.DataFrame, text=True):
'''Produce a raster plot, showing the time of each participants' steps
and the cluster they've been assigned to.
'''
fig, axes = plt.subplots(4, 1, figsize=(18, 12))
for i, start in enumerate([0, 12, 24, 36]):
raster_plot_row(cluster_matrix, dfx, start=start, stop=start+12, ax=axes[i], text=text)
plt.tight_layout()
plt.ylabel('Subject')
plt.xlabel('Time (s)')
def raster_plot_row(cluster_matrix, dfx, start=0, stop=90, text=True, ax=None):
'''Plot a single row of our raster plot, in the time window provided'''
if ax is None:
plt.figure(figsize=(18, 3))
plt.ylabel('Subject')
plt.xlabel('Time (s)')
else:
plt.sca(ax)
pal = sns.palettes.color_palette(n_colors=7)
from itertools import cycle
pal = cycle(pal)
X = dfx.values
subjects = dfx.index.values
subject_ix = np.arange(len(subjects))
steps = np.unique(cluster_matrix)
steps = steps[~np.isnan(steps)]
for step in steps:
color = next(pal)
for sx, subject in enumerate(subjects):
cm = cluster_matrix[sx]
t = X[sx, cm==step] # subject cluster times
t = t[(t >= start) & (t <= stop)]
n = len(t)
if n > 0:
if text:
for v in t:
plt.text(v, sx, int(step), color=color)
else:
plt.plot(t, np.repeat(sx, n), 'o', color=color)
plt.ylim(-1, len(subjects)+1)
plt.yticks(subject_ix+.5, subjects)
plt.xlim(start, stop)
raster_plot(initial_cluster_matrix, dfx)
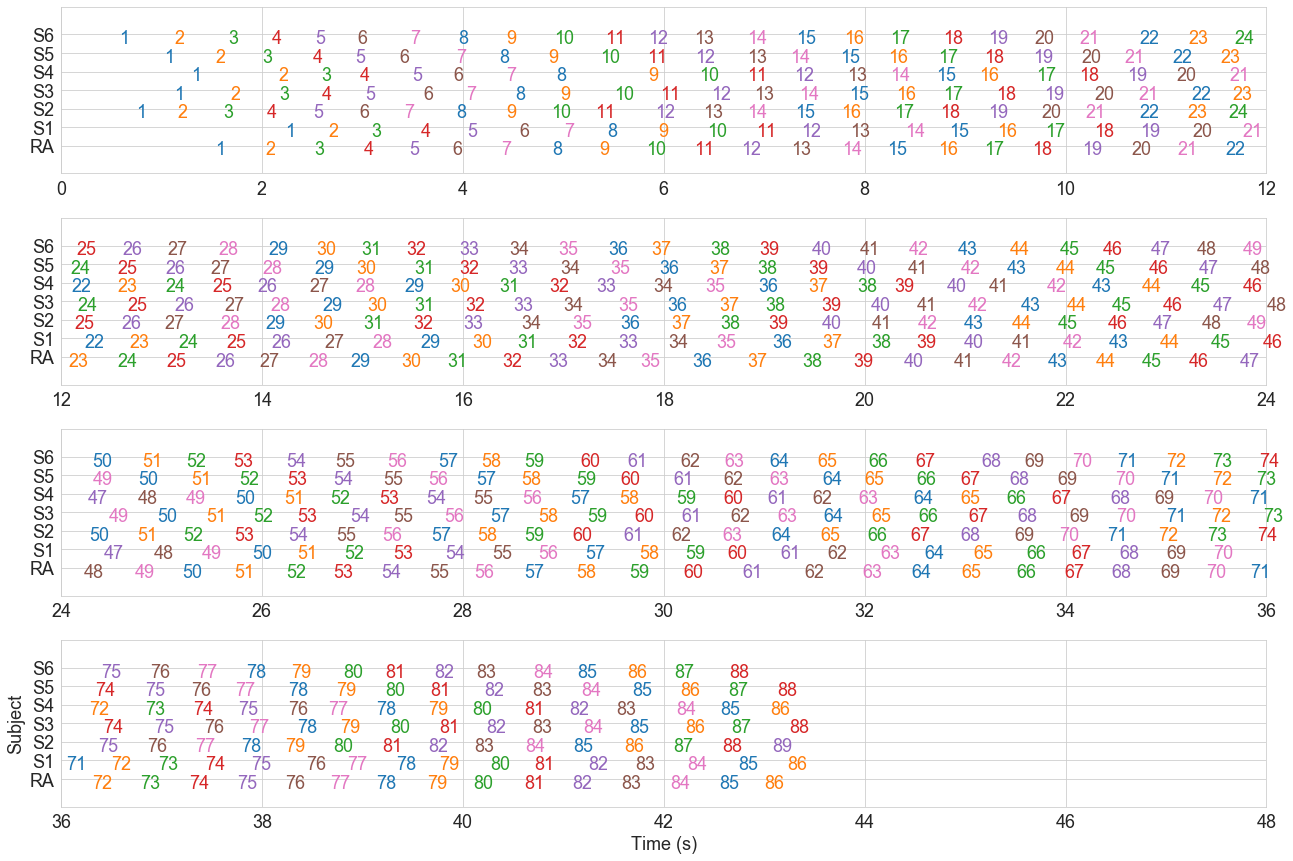
Clearly, the clusters are wrong. If we look at 6 seconds in, for instance, we see that all 7 people step at around the same time, but this is step 10 for the RA, step 9 for subject 1, step 12 for subject 2, and so on.
Automatic Clustering #
To address this, I use an automatic clustering algorithm from scikit-learn
to group the steps into temporal clusters.
There are a number of clustering algorithms available,
making different assumptions about the nature of the clusters you’re looking for,
and with different parameters to be tuned.
Some algorithms such as k-means and Gaussian mixture models require that you specify how many clusters you’re looking for. This is problematic here, since different groups end up with different numbers of beat clusters, and it’s not even clear even to us how many clusters there should be. For example, how many beats occur in the first two seconds of the plot above? It is possible to use model selection techniques to find the optimal number of clusters for some algorithms, such as Guassian mixture modelling, but this is time-consuming and complicated. K-means also assumes that all clusters have the same variance, which doesn’t work here since cluster variance goes up whenever people go out of time.
Other algorithms automatically figure out how many clusters to create,
based on some other criterion.
I found good results using the Mean Shift
algorithm,
which requires that you set a bandwidth parameter
dictating how broad individual clusters should be.
Results were best with bandwidth=0.25,
which seems consistent with the fact that particpants
were supposed to be stepping at 120 BPM, or once every 0.5 seconds.
# Step times as column vector, excluding NaNs
X = dfx.values
step_times = X[~np.isnan(X)].flatten().reshape(-1, 1)
# Fit model
model = skcluster.MeanShift(bandwidth=.25).fit(step_times)
# Cluster labels are not in order
# To reorder them, we generate a dict that maps
# the original labels to new, ordered ones.
labels = model.predict(model.cluster_centers_)
ordered_labels = model.predict(np.sort(model.cluster_centers_, 0))
label_dict = dict(zip(ordered_labels, labels))
label_dict[np.nan] = np.nan
print(label_dict)
{88: 0, 86: 1, 87: 2, 82: 3, 81: 4, 80: 5, 79: 6, 78: 7, 77: 8, 76: 9, 85: 10, 75: 11, 74: 12, 73: 13, 72: 14, 71: 15, 70: 16, 69: 17, 68: 18, 67: 19, 66: 20, 65: 21, 64: 22, 63: 23, 62: 24, 61: 25, 60: 26, 59: 27, 58: 28, 57: 29, 56: 30, 55: 31, 54: 32, 53: 33, 52: 34, 51: 35, 50: 36, 49: 37, 48: 38, 47: 39, 46: 40, 45: 41, 44: 42, 43: 43, 42: 44, 41: 45, 40: 46, 39: 47, 38: 48, 37: 49, 36: 50, 35: 51, 34: 52, 33: 53, 32: 54, 31: 55, 30: 56, 29: 57, 28: 58, 27: 59, 26: 60, 25: 61, 24: 62, 84: 63, 23: 64, 22: 65, 21: 66, 20: 67, 19: 68, 18: 69, 17: 70, 16: 71, 15: 72, 14: 73, 13: 74, 12: 75, 11: 76, 10: 77, 9: 78, 8: 79, 7: 80, 6: 81, 5: 82, 4: 83, 3: 84, 2: 85, 1: 86, 0: 87, 83: 88, nan: nan}
# Generate a matrix of ordered cluster labels from the clustering model
cluster_matrix = np.zeros_like(X)
for i in subjects:
for j in range(n_times):
x = X[i, j]
if not np.isnan(x):
label = model.predict(x.reshape(-1, 1))[0]
cluster_matrix[i, j] = label_dict[label]
else:
cluster_matrix[i, j] = np.nan
print(cluster_matrix)
[[ 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19.
20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 34. 35. 36. 37.
38. 39. 40. 41. 42. 43. 44. 45. 46. 47. 48. 49. 50. 51. 52. 53. 54. 55.
56. 57. 58. 59. 60. 61. 62. 64. 65. 66. 67. 68. 69. 70. 71. 72. 73. 74.
75. 76. 77. 78. 79. 80. 81. 82. 83. 84. 85. 86. 87. 88. nan nan nan]
[ 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20.
21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 34. 35. 36. 37. 38.
39. 40. 41. 42. 43. 44. 45. 46. 47. 48. 49. 50. 51. 52. 53. 54. 55. 56.
57. 58. 59. 60. 61. 62. 63. 64. 65. 66. 67. 68. 69. 70. 71. 72. 73. 74.
75. 76. 77. 78. 79. 80. 81. 82. 83. 84. 85. 86. 87. 88. nan nan nan]
[ 0. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17.
18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 34. 35.
36. 37. 38. 39. 40. 41. 42. 43. 44. 45. 46. 47. 48. 49. 50. 51. 52. 53.
54. 55. 56. 57. 58. 59. 60. 61. 62. 63. 64. 65. 66. 67. 68. 69. 70. 71.
72. 73. 74. 75. 76. 77. 78. 79. 80. 81. 82. 83. 84. 85. 86. 87. 88.]
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18.
19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 34. 35. 36.
37. 38. 39. 40. 41. 42. 43. 44. 45. 46. 47. 48. 49. 50. 51. 52. 53. 54.
55. 56. 57. 58. 59. 60. 61. 62. 63. 64. 65. 66. 67. 68. 69. 70. 71. 72.
73. 74. 75. 76. 77. 78. 79. 80. 81. 82. 83. 84. 85. 86. 87. 88. nan]
[ 1. 3. 4. 5. 6. 7. 8. 9. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20.
21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 34. 35. 36. 37. 38.
39. 40. 41. 42. 43. 44. 45. 46. 47. 48. 49. 50. 51. 52. 53. 54. 55. 56.
57. 58. 59. 60. 61. 62. 63. 64. 65. 66. 67. 68. 69. 70. 71. 72. 73. 74.
75. 76. 77. 78. 79. 80. 81. 82. 83. 84. 85. 86. 87. 88. nan nan nan]
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18.
19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 34. 35. 36.
37. 38. 39. 40. 41. 42. 43. 44. 45. 46. 47. 48. 49. 50. 51. 52. 53. 54.
55. 56. 57. 58. 59. 60. 61. 62. 63. 64. 65. 66. 67. 68. 69. 70. 71. 72.
73. 74. 75. 76. 77. 78. 79. 80. 81. 82. 83. 84. 85. 86. 87. 88. nan]
[ 0. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17.
18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 34. 35.
36. 37. 38. 39. 40. 41. 42. 43. 44. 45. 46. 47. 48. 49. 50. 51. 52. 53.
54. 55. 56. 57. 58. 59. 60. 61. 62. 63. 64. 65. 66. 67. 68. 69. 70. 71.
72. 73. 74. 75. 76. 77. 78. 79. 80. 81. 82. 83. 84. 85. 86. 87. nan]]
# Here's a function that does the same thing
def fit_meanshift_clusters(dfx: pd.DataFrame, bandwidth=.25) -> np.ndarray:
'''Cluster the step times using the MeanShift algorithm.
Returns participant × step cluster matrix'''
# Step times as column vector, excluding NaNs
X = dfx.values
step_times = X[~np.isnan(X)].flatten().reshape(-1, 1)
# Fit model
model = skcluster.MeanShift(bandwidth=.25).fit(step_times)
# Cluster labels are not in order
# To reorder them, we generate a dict that maps
# the original labels to new, ordered ones.
labels = model.predict(model.cluster_centers_)
ordered_labels = model.predict(np.sort(model.cluster_centers_, 0))
label_dict = dict(zip(ordered_labels, labels))
label_dict[np.nan] = np.nan
# Generate a matrix of ordered cluster labels from the clustering model
cluster_matrix = np.zeros_like(X)
n_subjects, n_times = X.shape
for i in range(n_subjects):
for j in range(n_times):
x = X[i, j]
if not np.isnan(x):
label = model.predict(x.reshape(-1, 1))[0]
cluster_matrix[i, j] = label_dict[label]
else:
cluster_matrix[i, j] = np.nan
return cluster_matrix
raster_plot(cluster_matrix, dfx)
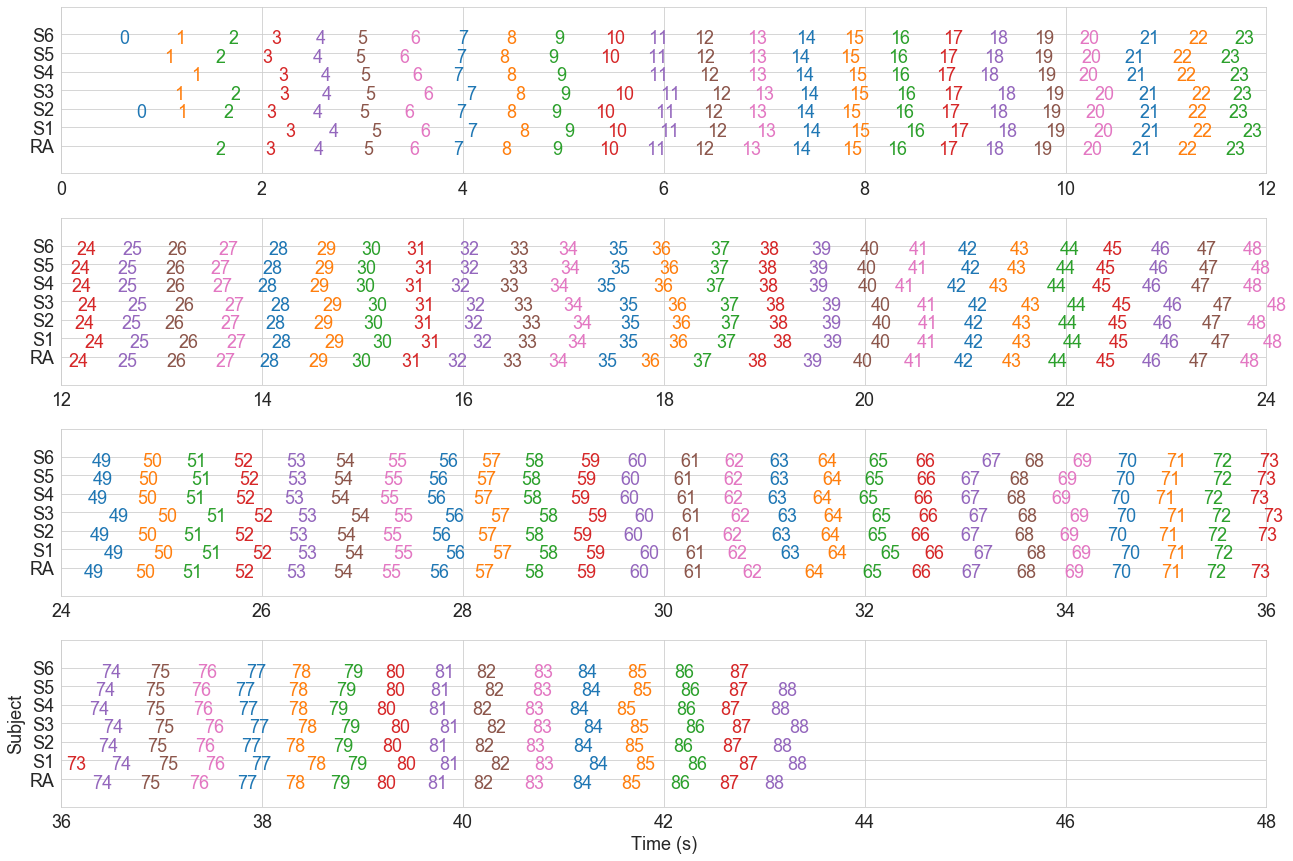
Better. Steps that occur at around the same time are now part of the same cluster.
Finally, we convert the step times and cluster labels back to format, and save them to file.
%mkdir -p data/clustered
step_df = dfx.reset_index().melt(id_vars='subject', value_name='time')
cluster_dfx = pd.DataFrame(cluster_matrix, index=dfx.index, columns=dfx.columns)
cluster_df = (cluster_dfx.reset_index()
.melt(id_vars='subject')
.rename({'value':'cluster'}, axis=1)
.sort_values(['step', 'subject']))
result = pd.merge(step_df, cluster_df,
on=['subject', 'step'], how='left')
result.to_csv('data/clustered/group%i_block%i.csv' % (group, block),
index=False)
result.head()
Edge Cases #
Although it works very well for the vast majority of our data (27 groups, two blocks each), this approach isn’t perfect. There are still some cases that aren’t clustered as we would expect. Here’s the worst example.
group, block = 2, 2
dfx = select_wide_data(all_data, group, block)
cluster_matrix = fit_meanshift_clusters(dfx)
raster_plot(cluster_matrix, dfx)
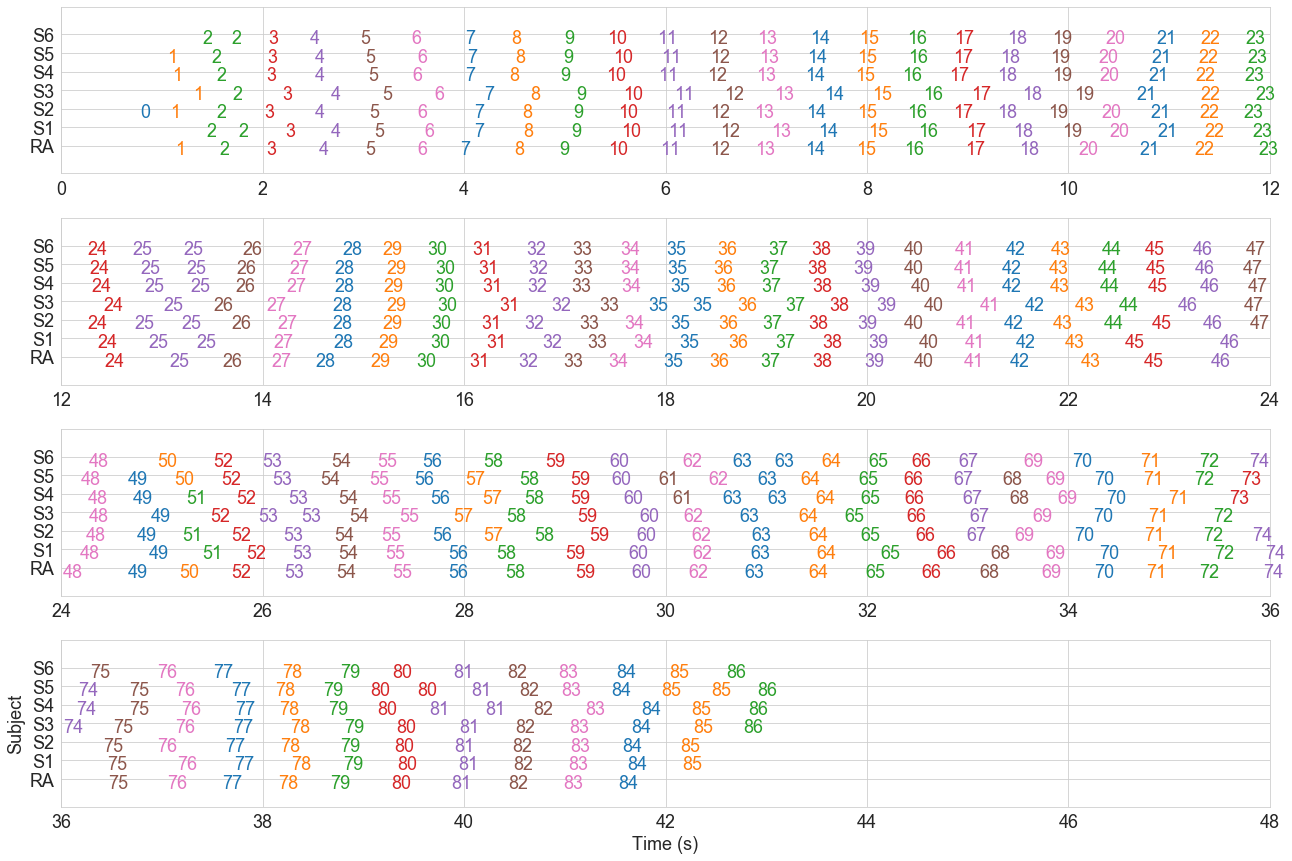
Cluster 25 contains steps that should really be split across two clusters, clusters 50 and 51 should probably be a single cluster. There are a few other issues, for example around cluster 68. Several of these issues arise because the clustering algorithm isn’t constrained to have only one step per person per cluster. There are a few approaches we could take to deal with these problems.
Exclude them #
For now, we limit our analyses to clusters of 7 steps. This is certainly the most reliable solution, and does not lead to any further issues in our analyses.
Constrain the clustering algorithm #
In principle, we could modify the code for
sklearn.cluster.MeanShift
to add the constraints we need.
This is likely to be difficult though.
Postprocess the result #
Alternatively, we could do the clustering as normal, but add some additional steps at the end to deal with abnormal clusters when they come up.
Manual fix #
Finally, we could just manually adjust the cluster result to deal with these very occasional edge cases.
This is probably the most time-effective way to actually fix the problem.
Fixing the abberant clusters might be quite time-consuming in a spreadsheet program,
but could be made much easier by using
matplotlib’s advanced features
to make the raster plots above interactive,
providing a GUI for modifying the cluster labels.
This is quite similar to some of the functionality
in the excellent mne package for M/EEG analyses.
Loop It #
Finally, the code below runs the clustering algorithm for every group, produces plots, and merges and saves the output.
%mkdir -p figures
%mkdir -p figures/clustering
# Duplicates of the functions defined above
def select_wide_data(all_data: pd.DataFrame,
group: int, block: int) -> pd.DataFrame:
'''Get wide data for this group, in this block'''
mask = (all_data['group']==group) & (all_data['block']==block)
df = all_data[mask] # Long format
dfx = df.pivot_table(index='subject', columns='step', values='time') # Wide format
return dfx
def raster_plot(cluster_matrix: np.ndarray, dfx: pd.DataFrame, text=True):
'''Produce a raster plot, showing the time of each participants' steps
and the cluster they've been assigned to.
'''
fig, axes = plt.subplots(4, 1, figsize=(18, 12))
for i, start in enumerate([0, 12, 24, 36]):
raster_plot_row(cluster_matrix, dfx, start=start, stop=start+12, ax=axes[i], text=text)
plt.tight_layout()
plt.ylabel('Subject')
plt.xlabel('Time (s)')
def raster_plot_row(cluster_matrix, dfx, start=0, stop=90, text=True, ax=None):
'''Plot a single row of our raster plot, in the time window provided'''
if ax is None:
plt.figure(figsize=(18, 3))
plt.ylabel('Subject')
plt.xlabel('Time (s)')
else:
plt.sca(ax)
pal = sns.palettes.color_palette(n_colors=7)
from itertools import cycle
pal = cycle(pal)
X = dfx.values
subjects = dfx.index.values
subject_ix = np.arange(len(subjects))
steps = np.unique(cluster_matrix)
steps = steps[~np.isnan(steps)]
for step in steps:
color = next(pal)
for sx, subject in enumerate(subjects):
cm = cluster_matrix[sx]
t = X[sx, cm==step] # subject cluster times
t = t[(t >= start) & (t <= stop)]
n = len(t)
if n > 0:
if text:
for v in t:
plt.text(v, sx, int(step), color=color)
else:
plt.plot(t, np.repeat(sx, n), 'o', color=color)
plt.ylim(-1, len(subjects)+1)
plt.yticks(subject_ix+.5, subjects)
plt.xlim(start, stop)
def fit_meanshift_clusters(dfx: pd.DataFrame, bandwidth=.25) -> np.ndarray:
'''Cluster the step times using the MeanShift algorithm.
Returns participant × step cluster matrix'''
# Step times as column vector, excluding NaNs
X = dfx.values
step_times = X[~np.isnan(X)].flatten().reshape(-1, 1)
# Fit model
model = skcluster.MeanShift(bandwidth=.25).fit(step_times)
# Cluster labels are not in order
# To reorder them, we generate a dict that maps
# the original labels to new, ordered ones.
labels = model.predict(model.cluster_centers_)
ordered_labels = model.predict(np.sort(model.cluster_centers_, 0))
label_dict = dict(zip(ordered_labels, labels))
label_dict[np.nan] = np.nan
# Generate a matrix of ordered cluster labels from the clustering model
cluster_matrix = np.zeros_like(X)
n_subjects, n_times = X.shape
for i in range(n_subjects):
for j in range(n_times):
x = X[i, j]
if not np.isnan(x):
label = model.predict(x.reshape(-1, 1))[0]
cluster_matrix[i, j] = label_dict[label]
else:
cluster_matrix[i, j] = np.nan
return cluster_matrix
def do_block(group, block, plot=True):
'''Put the whole pipeline together'''
print('Group %i - Block %i' % (group, block))
dfx = select_wide_data(all_data, group, block)
cluster_matrix = fit_meanshift_clusters(dfx)
raster_plot(cluster_matrix, dfx)
# Initial order
n_subjects, n_times = dfx.shape
steps = np.arange(n_times)
subjects = np.arange(n_subjects)
cluster_ids = dfx.columns.values
initial_cluster_matrix = np.repeat(cluster_ids, n_subjects).reshape((n_times, n_subjects)).T
# Plot and save
if plot:
raster_plot(initial_cluster_matrix, dfx)
plt.suptitle('Group %i - Block %i - Initial Labels' % (group, block))
plt.savefig('figures/clustering/g%i_b%i_initial.png' % (group, block))
plt.close()
# Mean Shift Clustering
cluster_matrix = fit_meanshift_clusters(dfx)
if plot:
raster_plot(cluster_matrix, dfx)
plt.suptitle('Group %i - Block %i - MeanShift Clustered Labels' % (group, block))
plt.savefig('figures/clustering/g%i_b%i_meanshift.png' % (group, block))
plt.close()
## Export
step_df = dfx.reset_index().melt(id_vars='subject', value_name='time')
cluster_dfx = pd.DataFrame(cluster_matrix, index=dfx.index, columns=dfx.columns)
cluster_df = (cluster_dfx.reset_index()
.melt(id_vars='subject')
.rename({'value':'cluster'}, axis=1)
.sort_values(['step', 'subject']))
result = pd.merge(step_df, cluster_df,
on=['subject', 'step'], how='left')
result['group'] = group
result['block'] = block
return result
results = []
for (group, block), _ in all_data.groupby(['group', 'block']):
result = do_block(group, block)
results.append(result)
Group 1 - Block 1
Group 1 - Block 2
Group 2 - Block 1
...[and so on]...
final_results = pd.concat(results)
final_results.head()
| subject | step | time | cluster | group | block | |
|---|---|---|---|---|---|---|
| 0 | RA | 1 | 1.534 | 2.0 | 1 | 1 |
| 1 | S1 | 1 | 2.229 | 3.0 | 1 | 1 |
| 2 | S2 | 1 | 0.751 | 0.0 | 1 | 1 |
| 3 | S3 | 1 | 1.120 | 1.0 | 1 | 1 |
| 4 | S4 | 1 | 1.293 | 1.0 | 1 | 1 |
final_results.to_csv('data/clustered.csv', index=False)